
Claude Sonnet vs Opus: Why 99% of Users Choose Sonnet
 Posted By: Billie Miller
Posted By: Billie Miller- Category: Hot Topic
- Updated On: March 31, 2026
"Are you seeing big difference between Sonnet vs. Opus?" -- Reddit❓
As of March 2026, both Claude Sonnet 4.6 and Opus 4.6 have been released, just a little over 10 days apart. Surprisingly, Sonnet 4.6 has outperformed Opus 4.6 in several tests. You may wonder—how can it be better while being so much cheaper?
If you're a beginner, this guide is for you. We'll compare Claude Sonnet vs Opus in key features, pricing, speed, and use cases, and help you decide which one best fits your needs.

Part 1. Claude Sonnet vs Opus: Key Differences at a Glance
If you want to figure out which Claude model is right for you in under 1 minute, check out Part 5. Based on Anthropic's official comparison table, and after simplifying the key points, here's what you probably care about most:
| Model | Key Features | Pricing | Speed | Best For |
|---|---|---|---|---|
| Claude Sonnet 4.6 | 1M context, strong reasoning, excellent office tasks & financial analysis, high efficiency | ~$3 input / $15 output (per 1M tokens) | Fast, ~2x quicker responses | Daily workflows, writing, coding, business tasks, students & professionals |
| Claude Opus 4.6 | 1M context, deeper reasoning, stronger agentic coding & complex analysis | ~$5 input / $25+ output (per 1M tokens) | Slower, optimized for depth | Advanced research, large codebases, high-stakes decision-making |
Claude Sonnet 4.6: Key Performance Highlights
While Opus 4.6 is slightly better in more technical areas like coding and search, it's fair to say that Sonnet 4.6 can handle 99% of everyday tasks.
First, Sonnet 4.6 achieved a breakthrough score of 1633 in Office Tasks. This reflects its real-world efficiency and accuracy when handling everyday work like document collaboration, office workflows, and routine tasks.
Second, Sonnet 4.6 can understand reports, analyze them, and even support decision-making. Anthropic reports a score of 63.3%, which may not seem very high at first. But when you consider that Gemini 3 Pro and GPT-5.2 scored 55.2% and 59.0% respectively, it puts things into perspective.
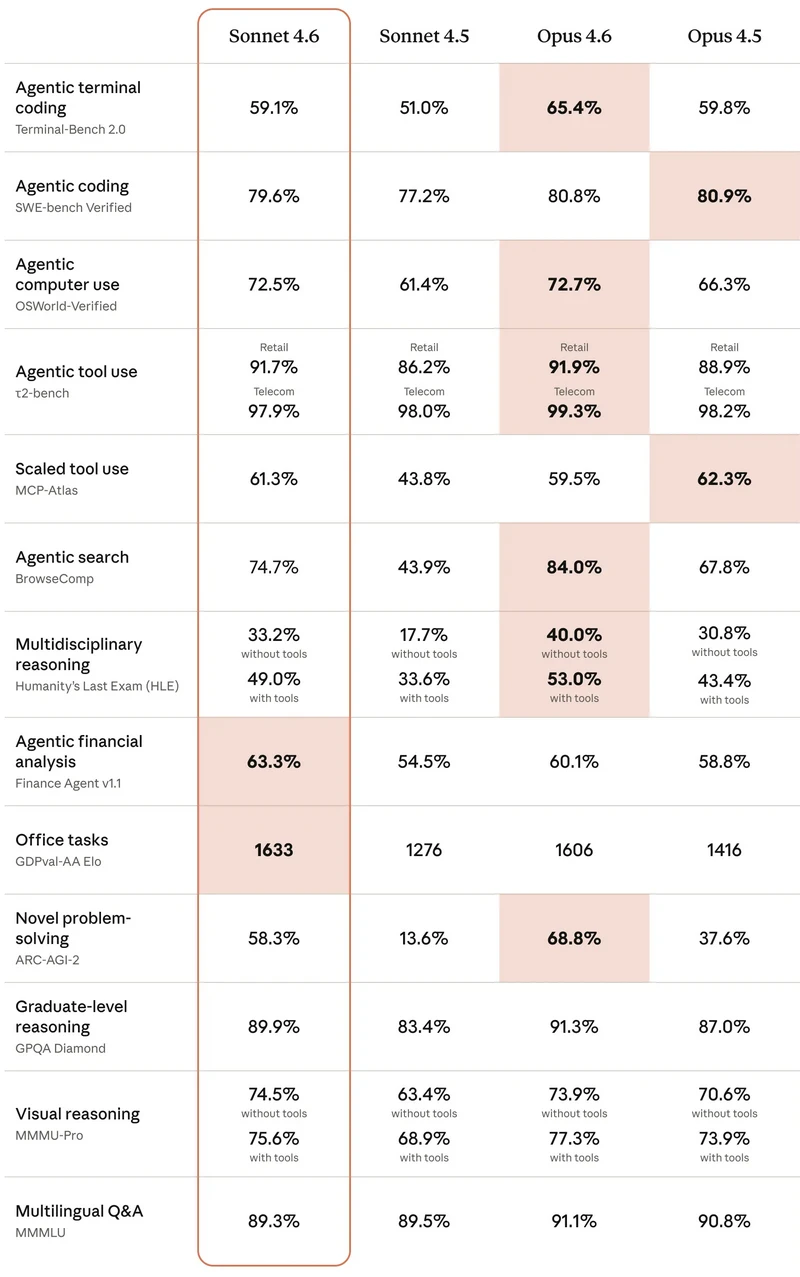
Note: Data sourced from Anthropic in March, 2026; comparison limited to Sonnet and Opus.
Part 2. Why 99% of Users Choose Claude Sonnet?
Sonnet 4.6 could be an all-rounder in everyday versatility, and this model is their most capable Sonnet model yet. It trims the unnecessary computing overhead to boost speed, while retaining the core intelligence needed to handle 99% of complex tasks. That's why Sonnet is the ultimate balance of performance and efficiency.
What Makes Sonnet Stand Out?
The projects where Claude Sonnet 4.6 performed best were Agentic Financial Analysis and Office Tasks. At the same time, the other projects show a difference of just a few percentage points compared to Opus. Let's know more about what these 2 advantages of Sonnet can do for us?
Agentic Financial Analysis
Agentic Financial Analysis requires long-term memory for trends and historical data, as well as the ability to assess risks and handle calculations or charts. Claude Sonnet 4.6 excels at these tasks with its advanced Agent capabilities. This makes it perfect for personal finance, small business decisions, and freelancers.
Office Tasks
Agentic Financial Analysis proves it can think deeply, while Office Tasks show it can actually do the work.
- First, with one instruction, it can handle tasks like writing emails, creating spreadsheets, and organizing documents.
- Second, it works smoothly with tools like Word, Excel, and PowerPoint.
- Third, even if you give a simple instruction, it understands that you want a detailed result—not just a rough draft.
- Then, it delivers consistent performance. Office Tasks cover most people's everyday needs for AI.
That's why Sonnet 4.6 is especially suitable for students and office workers.
Why Sonnet 4.6 Beats Opus for Most People (Generally)?
Even with Opus's recent price drop, Sonnet 4.6 is still the better choice for most users. It delivers near-flagship performance at a fraction of the cost and responds almost twice as fast as Opus. While Opus shines in extremely complex reasoning, Sonnet 4.6 hits the “sweet spot” for 99% of everyday work—offering fast, efficient results without sacrificing the intelligence needed for medium-to-high complexity tasks. For most people, paying extra for Opus simply isn't worth it.
1. Consistent Writing:
Rating:★★★★☆
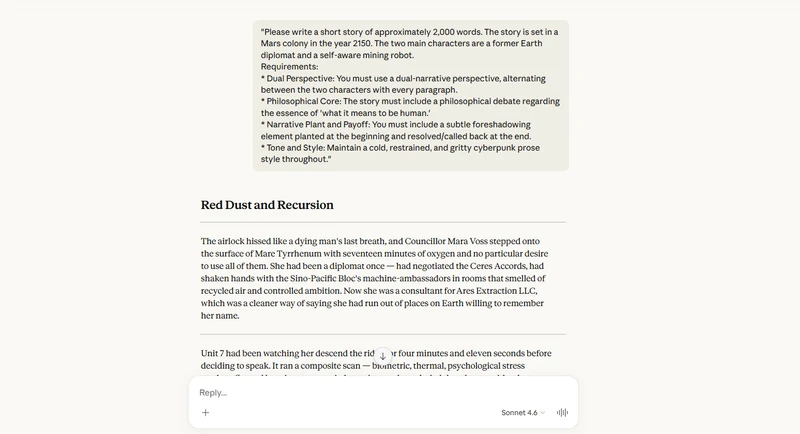
I input a prompt into Claude Sonnet 4.6 asking it to write a medium-length novel, and it produced a 1,732-word story titled Red Dust and Recursion. It kept everything consistent—Sonnet 4.6 didn't forget the character names or plot details I set up at the beginning. Even as the story got longer, the paragraphs flowed naturally, with no awkward transitions or repeated descriptions.
The writing style remained consistent throughout, giving the impression that it was all written by a single author. The only thing I think could be improved is that other models usually provide an outline first, but this response did not include one.
Please write a short story of approximately 2,000 words. The story is set in a Mars colony in the year 2150.
The two main characters are a former Earth diplomat and a self-aware mining robot.
Requirements:
1. Dual Perspective: You must use a dual-narrative perspective, alternating between the two characters with every paragraph.
2. Philosophical Core: The story must include a philosophical debate regarding the essence of 'what it means to be human.'
3. Narrative Plant and Payoff: You must include a subtle foreshadowing element planted at the beginning and resolved/called back at the end.
4. Tone and Style: Maintain a cold, restrained, and gritty cyberpunk prose style throughout.
2. Structured Output:
Rating:★★★★★
The output is a valid JSON code block with no formatting errors. It correctly recognized the phrase "4.5 million" in the text and converted it to the numeric value 4,500,000. Many models might mistakenly output it as the string "4.5 million" or keep it as a decimal.
It successfully ignored the unrelated "1.2 million" (Titan mission) and accurately captured the budget for the current project. It also filtered out vague references like "dozens of subcontractors," extracting only the three clearly mentioned core members: Alice, Bob, and Charlie.
The text mentioned "focused urgency", which could easily lead an AI to mark the priority as high. However, this response correctly recognized the official conclusion at the end—medium—showing strong semantic reasoning for priority decisions.
The reply contains no extra phrases like "Here is the JSON" or "Okay, here's the extracted information," fully meeting the strict requirement of “no preamble or postscript.”
Extract key information from the provided text and output it strictly in JSON format.
Constraints:
No preamble or postscript: Do not include any introductory text, explanations, or "Here is the JSON" remarks. Return only the JSON code block.
Field Requirements:
project_name (string)
budget_usd (number: extract the numerical value only, e.g., 4500000)
priority (enum: must be one of "high", "medium", or "low")
team_members (array of strings: include only the core individuals mentioned)
Input Text:
"Following the strategic review of our deep-space initiatives, we have officially greenlit 'Project Uranus.' While our previous endeavors like the Titan mission operated on a shoestring budget of 1.2 million, this new undertaking is significantly more ambitious, with a projected capital allocation of 4.5 million USD. Currently, the internal atmosphere is one of focused urgency due to the tight launch window; however, since we are strictly in the foundational 'Phase 1' architecture stage, the steering committee has officially designated the current priority level as medium. The core execution of this phase is being spearheaded by Alice as the Lead Architect and Bob as the Operations Manager. They are supported by Charlie, who is exclusively handling the technical infrastructure. While dozens of subcontractors are involved, these three remain the only core members at this stage of the lifecycle."

3. Insightful Analysis:
Rating:★★★★☆
I received a 919-word report that includes tables. After reading it carefully, you can see that the insights are genuinely there—but they're not groundbreaking. Instead, they show controlled and deliberate leaps in thinking.
Sonnet 4.6 is quite specific, especially with its 18-36 month timeline. It's great for setting high-level direction, but it doesn't yet reach the level of detailed, executable steps.
If it further explored multi-round scenarios—such as “what if competitors also start open-sourcing evaluation frameworks, and how should we respond?”—that level of reflection would better highlight its ability to generate truly insightful analysis.
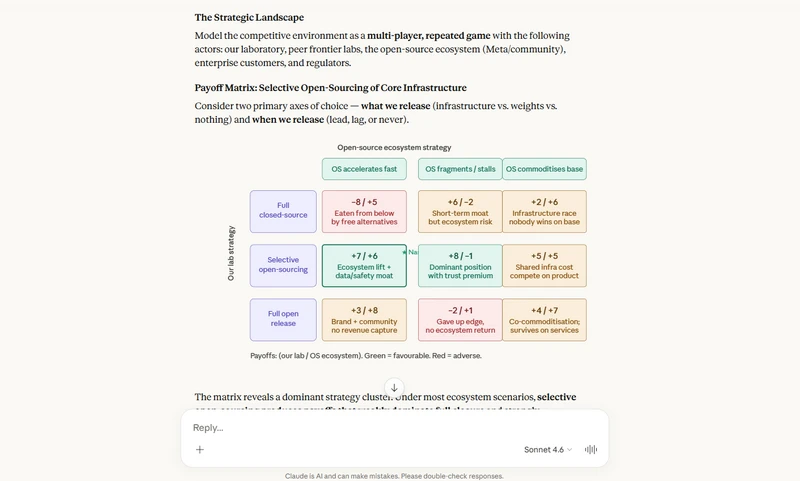
"Act as the Chief Strategy Officer (CSO) of a leading AI laboratory. You are tasked with drafting an internal strategic assessment addressing the tension between the 'rapidly accelerating capabilities of the open-source community' and the 'necessity of maintaining a competitive edge through closed-source commercial models.'
Requirements:
Game-Theoretic Framework: Use a game-theoretic model to analyze the potential payoffs and risks if the company chooses a 'selective open-sourcing' strategy for core infrastructure components.
Hidden Risk Identification: Identify one specific, critical risk factor that is currently being overlooked by the majority of mainstream industry analysts.
Non-consensus Recommendation: Provide a 'non-consensus' strategic recommendation. Explain why this counter-intuitive path could serve as a sustainable long-term moat for the company, rather than a disadvantage."
Part 3. Why the Opus Price Cut Still Isn't Enough?
In this section, you'll learn about the strengths of Claude Opus and its recent price changes, and whether there are better alternatives like Claude Sonnet or Gemini 3 Pro—so you can decide if it's the right choice for you.
What Makes Claude Opus Stand Out?
The creator of The Nerdy Novelist believes that Opus has more nuanced, human-like writing. When working with highly serious, error-sensitive documents, Opus is more reliable than Sonnet in handling facts. When writing long novels or detailed reports, Opus does a better job of remembering subtle character traits, so the content feels more consistent without contradictions.
Although both support a 1M token context, real-world testing shows that Opus has higher "memory quality". For example, if you ask it to include five specific keywords, keep each sentence under 10 words, and maintain a certain tone, Opus performs more consistently.
That's why you may need Opus 4.6 only for complex tasks—such as writing in-depth industry reports, analyzing dozens of financial documents with risk assessment, or navigating and refactoring massive codebases.
Why Price Cut Isn't Enough?
But if that's the case, why do we still say the price cut isn't enough? In most real-world tasks, Sonnet 4.6 performs almost the same as Opus 4.6—and in some cases, like story flow and coherence, it can even do better. However, even after the price drop, Opus still costs about twice as much as Sonnet (around $25 per 1M output tokens vs $15).
Interestingly, Sonnet 4.6 can sometimes write prose more naturally, with fewer overly dramatic, “AI-sounding” phrases than Opus. This means that for 99% of tasks, there's little reason for users to pay double the price for a 5% improvement—or sometimes even a slight downgrade.
Are Other Tools Still Competitive?
Since its release, Claude Sonnet 4.6 has been the clear “best value” model. It offers a 1M token context (though real recall ability still has room to improve) and comes extremely close to Opus in creative writing and logic, making it capable of handling most workflows that Opus does.
Other tools are still competitive: writing with Gemini 3 is smooth and hassle-free, and the release of Gemini 3.1 may further challenge Claude's position. OpenAI's Codex remains a classic for coding and logical tasks, excelling in workflows where Claude is less specialized. However, for human-like, natural writing, Sonnet 4.6 currently has the edge.
| Model | Key Features | Pricing | Speed | Best For |
|---|---|---|---|---|
| Gemini 3.1 Pro | 2M+ context, strong multimodal capabilities, handles large-scale documents and media | $2 input / $12 output (per 1M tokens) | Fast, smooth performance | Long-context tasks, multimodal workflows, large document processing |
| GPT-5.3 Codex | Optimized for coding & engineering logic, strong structured reasoning | $5 input / $15 output (per 1M tokens) | Medium, optimized for accuracy | Programming, debugging, complex codebases, technical workflows |
This article will review HitPaw Video Enhancer and explore its features, pros & cons, its cost, and other options.
Part 4. What Real Users Say About Sonnet vs Opus
Example 1 Bigger Isn't Better: Why 30K Words Beats 1M Context
I tried feeding an entire book into Sonnet 4.6, but the retrieval quality wasn't great. Even though it supports up to 1 million tokens for input and output, it tends to miss some sections—especially content from the middle of the book.
After multiple tests, my recommendation is to keep the input around 30,000 words. At that range, its context understanding and retrieval performance can really impress you.
If you go beyond that, the results become less reliable. You may end up spending more time (and money) reviewing and fixing the output, which kind of defeats the purpose.
Example 2 When Instructions Get Ignored: SVG vs Emoji Frustration
When I used Sonnet 4.6 to create some simple online mini games, it didn't follow my instruction to use SVG format. Instead, it used emoji icons in the game interface, which I really didn't like. Also, the tokens I purchased were used up after testing fewer than three small games, which was quite frustrating.
Example 3 Efficiency vs Emotion: Sonnet vs Opus in Creative Writing
I've been using both models to help write a high-fantasy novel series, and their “personalities” feel very different. Sonnet 4.6 is super efficient. It follows every plot point I give it and keeps the writing clean and consistent. I usually rely on it for world-building and character profiles.
But when it comes to the emotional depth of an important scene, Opus 4.6 still stands out. I asked both models to write a tense reunion between two siblings who had been apart for years. Sonnet's version was technically solid, but it felt more like a well-written script. Opus, however, picked up on subtle emotions I didn't even mention. It described things like the heavy silence and small moments of hesitation in a very human way.
Part 5. Which Claude Should You Use Today?
| Use Case | Recommended Model | Why It Works | Trade-Offs |
|---|---|---|---|
| Daily Workflows (Writing, Office Tasks, Business) | Claude Sonnet 4.6 | Fast, cost-efficient, handles 99% of real-world tasks with strong reasoning and consistency | Slightly less depth in highly complex or nuanced tasks |
| Content Creation (Blogs, Stories, General Writing) | Claude Sonnet 4.6 | Natural, clean writing style with strong structure and flow | Less emotional depth compared to Opus in key scenes |
| Creative Writing (Emotional, High-Impact Scenes) | Claude Opus 4.6 | Better at subtle emotions, subtext, and human-like nuance | Higher cost, slower responses |
| Advanced Research & Strategy Analysis | Claude Opus 4.6 | Stronger deep reasoning and more reliable for high-stakes decisions | Costs nearly 2x more than Sonnet |
| Coding & Large Codebases | Claude Opus 4.6 | More consistent in complex logic and long-context memory | Slower and more expensive |
| Budget-Conscious Users | Claude Sonnet 4.6 | Best price-to-performance ratio, fast responses, reliable output | May require occasional manual refinement for edge cases |
| Long Context Tasks (Books, Large Inputs) | Claude Sonnet 4.6 (with ~30K words) | Strong retrieval within optimal range, efficient processing | Performance drops with extremely large inputs (100K+ words) |
Best Model for AI Image & Video Prompts
Put the AI prompts generated by Claude into the image and video generator in Any Video Converter. It can accurately absorb the details in the prompts and get something emphasized carefully. As a result, even unoptimized prompts can still produce good results in AVC.
- Best For: AI video workflows, prompt-based video generation, format conversion
- Why It Stands Out: Supports a wide range of formats, easy to use, and integrates well with AI-generated media pipelines
- Use Case: Convert AI-generated clips, optimize video assets, and streamline your creative workflow
In short, pair a strong writing model like Claude Sonnet 4.6 (for prompt generation) with Any Video Converter (for processing output), and you get a smooth end-to-end AI content workflow.
Try it online: Free AI Video Generator from Image: Turn Photo to Video
FAQ About Claude Sonnet vs Opus
Is Claude Opus better than Sonnet?
Claude Opus might be the powerhouse, but Sonnet performs just as well in daily use. Why pay twice as much for a marginal gain? For almost everyone, Sonnet is the smarter, more cost-effective choice.
Read More: 5 Best CapCut Alternatives for Video Editing
Should I use Sonnet or Opus for coding at the beginning?
Claude Sonnet 4.6 is the best AI coding model ever. Based on WorldofAI's evaluation, Sonnet 4.6 delivers near-Opus level intelligence with superior speed and affordability. It responds twice as fast as Opus, providing developers with a much smoother real-time coding experience. Even though it costs only one-fifth as much, it still has a 1M context window.

Discover the truth about AVCLabs Video Enhancer AI cracked versions, potential risks, and legal ways to get AVCLabs for free in 2026. Learn more > >
Conclusion
The article mentions that 99% of people would choose Claude Sonnet. The reason isn't because its model completely outperforms Claude Opus, but because Sonnet is sufficient for 99% of the work. It's fast, efficient, and much more cost-effective. If your projects also involve AI-generated images or video content, you can pair Claude Sonnet with a tool like Any Video Converter to upgrade your workflow. This combination lets you save time and maximize output quality.



